Autoregressive and Hybrid Open-Source TTS Models Review
Wed Jun 12 2024 • Andrey Paznyak

Read the Full Series of ML TTS exploration
- Part 1: Intro, Little Theory and Math 📘
- Part 2: Autoregressive models world 🌍
- Part 3: Non-autoregressive models hideout 🕵️♂️
- 👉Part 4: Autoregressive and hybrid models review 📊
- Part 5: Non-autoregressive models review📝
- Part 6: DelightfulTTS implementation and training 🛠️
AR and hybrid models

Typical hybrid models
In the following sections, I will delve into the realm of autoregressive (AR) text-to-speech models, renowned for their ability to capture intricate sequential dependencies and generate expressive, natural-sounding speech. While exploring their architectures, training methodologies, and key innovations. Despite the challenges, AR models have been at the forefront of speech synthesis research.
SunoAI Bark
My research has begun with the discovery of an incredible open-source solution that can produce incredible results: SunoAI Bark Bark is obviously AR model, but how it works? I found this great repo: audio-webui and author tried to found out how bark works, but:
📓 Note
I’m still unsure how bark works. I am trying to figure out how it works though. My current knowledge goes here.
The author is researching voice cloning using the SunoAI Bark model and identified three different models used in the generation process: Semantics, Coarse, and Fine. The author notes that the current method of generating semantic tokens is problematic, as it generates tokens based on the input text rather than the actual audio. The author proposes three potential way for creation of speaker files for voice cloning:
- Find out how Bark generates semantic tokens (may not be publicly available).
- Train a neural network to convert audio files to semantic tokens (time-consuming, but effective).
- Use a speech converter to change the input audio without editing semantics (not perfect, but better than current methods).
The author has implemented Method 3 using coqui-ai/TTS and achieved decent voice cloning results, but with limitations.
Results: Decent voice cloning, not near perfect though. Better than previous methods, but struggles with some voices and accents. These issues lie in the transfer step.
They also explored Method 1, but were unable to find a suitable model.
Pre: It looks like bark uses AudioLM for the semantic tokens! I’m not sure if they use a different model though. I’ll have to test that. But if they don’t use a pre-trained model. I can do step 2.
Results: No, it doesn’t look like i can find a model, i did succeed in creating same-size vector embeddings, but the vectors use the wrong tokens.
Method 2, which involves creating a quantizer based on data, has shown promising results, achieving convincing voice cloning with some limitations.
Pre: What if instead of training a whole model, i only create a quantizer based on a bunch of data?
Results: Successful voice cloning, can be very convincing. Still some limitations. But better than anything I’ve seen done with bark before.
I can’t tell you more, please, share any details if you find better explanations of the Bark. AR nature of the model is obvious, that’s for sure. I faced with the limitations from the first touch — model can’t generate audio more than 13–14 sec length. Several issues about this problem are here:
Comment about it from issue #36 Inquiry on Maximum input character text prompt Length:
right now the output is limited by the context window of the model (1024) which equates to about 14s. So text should be around that duration (meaning ~2–3 sentences). For longer texts you can either do them one at a time (and use the same history prompt to continue the same voice) or feed the first generation as the history for the second. i know that that’s still a bit inconvenient. will try to add better support for that in the next couple of days
You can implement the following approach, split sentences and synthesize the audio chunks:
Also you can use batching:
But the butch generation creates a new problem. The quality of the audio is dramatically reduced, and it generates strange noises, much more often than in the case of generation in order. I found a great description in the comment: output quality seems worse if you pack it like that One more problem that I found is empty sounds if your text chunks are different sizes. Sometimes it’s a random noise like background voices etc. So, you need to split the text carefully, it’s very important. Bark occasionally hallucinates, which can lead to unexpected and inaccurate results. Unfortunately, it is impossible to detect this issue during the generation process, making it challenging to identify and correct. Furthermore, even during the review process, hallucinations can be difficult to spot, as they may be subtle or blend in with the rest of the generated content. This can result in incorrect or misleading information being presented as factual, which can have serious consequences in certain applications.
SunoAI summary
From what I understand, the issue of long context is not a priority for the Bark team and is largely being overlooked in the issues discussion. The only solution they’ve proposed is to use batches, but this approach has its limitations and doesn’t work well. Moreover, due to the text context, it can’t be processed accurately. Specifically, a small context of 2–3 sentences tends to disregard what happened in the previous passage, which can significantly impact the intonation and tempo of a speaker. Bark occasionally hallucinates, which can lead to unexpected and inaccurate results.
VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Samples on the demo page. VALL-E is a novel language model approach for text-to-speech (TTS) synthesis that leverages large-scale, diverse, and multi-speaker speech data. Unlike traditional cascaded TTS systems, VALL-E treats TTS as a conditional language modeling task, using discrete audio codec codes as intermediate representations. This approach enables VALL-E to synthesize high-quality, personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Key Components:
- Neural Codec Model: VALL-E uses a pre-trained neural audio codec model, EnCodec, to convert audio waveforms into discrete acoustic codes. This model is trained on a large dataset of speech and can reconstruct high-quality waveforms even for unseen speakers.
- Language Model: VALL-E is trained as a language model, using the discrete acoustic codes as input and output. This allows the model to learn the patterns and structures of speech, enabling it to generate coherent and natural-sounding speech.
- In-Context Learning: VALL-E has strong in-context learning capabilities, similar to GPT-3, which enables it to adapt to new speakers and acoustic environments with minimal additional training data.
The Problem Formulation is valid for Bark as well (except dimensions): Given a dataset D = {xᵢ, yᵢ} where y is an audio sample and: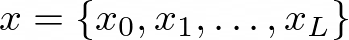
is its corresponding phoneme transcription, we use a pre-trained neural codec model to encode each audio sample into discrete acoustic codes, denoted as: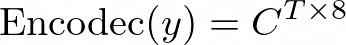
where C represents the two-dimensional acoustic code matrix, and T is the downsampled utterance length. The row vector of each acoustic code matrix: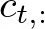
represents the eight codes for frame t and the column vector of each acoustic code matrix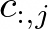
represents the code sequence from the j-th codebook, where j ∈ {1, …, 8}. After quantization, the neural codec decoder is able to reconstruct the waveform, denoted as: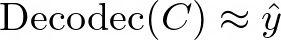
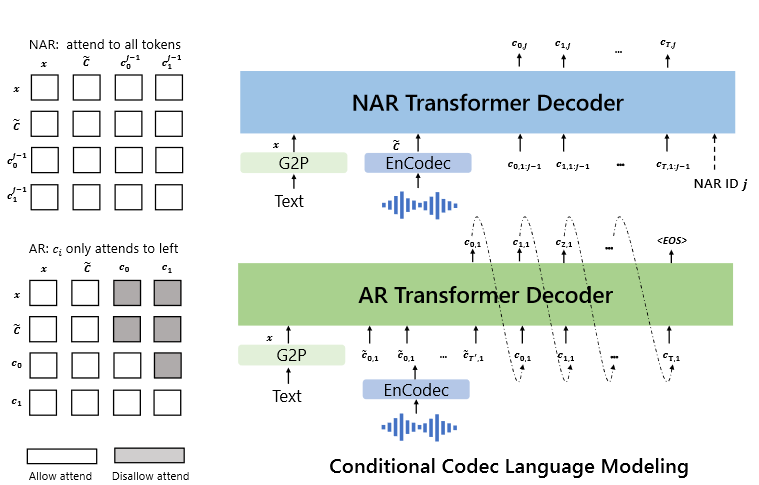
Vall-E schema
Based on the paper, it appears that the proposed model combines the principles of Autoregressive (AR) and Non-Linear Autoregressive (NAR) models:
The combination of the AR model and the NAR model provides a good trade-off between speech quality and inference speed. On the one hand, the rate of the generated speech should be consistent with the enrolled recording, and it is hard to train a length predictor for different speakers since their speaking speed may be very diverse. In this case, the AR model is a more natural choice with its flexibility for acoustic sequence length prediction. On the other hand, for the consecutive stages, as the number of output slots follows the sequence length of the first stage, NAR can reduce the time complexity from O(T) to O(1). Overall, the prediction of C can be modeled as:
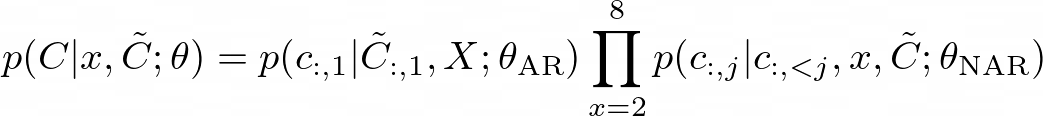
VALL-E implementations Note that there is currently no official implementation of VALL-E available. Even ETA for the official release is unknown VALL-E ETA? The official repository currently contains an empty space, awaiting further updates. However, for those interested in experimenting with VALL-E, an unofficial PyTorch implementation is available at unofficial PyTorch implementation of VALL-E. This implementation can be trained on a single GPU and is widely used in the community.
After eight hours of training, the model can synthesize natural speech!
code branch `position` PR #46
egs https://github.com/lifeiteng/vall-e/tree/position/egs/ljspeech
synthesised speech https://github.com/lifeiteng/vall-e/tree/position/egs/ljspeech/demos
The next step is to verify `in-context learning capabilities` of VALL-E on a large dataset.
And I found one more training story: After 100 epochs training, the model can synthesize natural speech on LibriTTS
I trained vall-e on LibriTTS about 100 epochs (took almost 4 days on 8 A100 GPUs) and I obtained plausible synthesized audio.
Here is a demo.
[1] prompt : prompt_link synthesized audio: synt_link
[2] prompt : prompt_link ground truth : gt_link synthesized audio: synt_link
[3] prompt : prompt_link synthesized audio : synt_link
[4] prompt : prompt_link ground truth: gt_link synthesized audio : synt_link
The model I trained has worse quality than the original vall-e because of the dataset amount. However, it has promising quality in clean audio. I’m not sure whether I can share my pre-trained LibriTTS model. If I can, I would like to share the pre-trained LibriTTS model.
Model weights:
Sorry for late reply. This is the model that I trained.
google drive link: https://drive.google.com/file/d/1pKvS56NnzVCYqhbjoFqL_JQ8i32UixbL/view?usp=sharing
One more unofficial PyTorch implementation of VALL-E, based on the EnCodec tokenizer. VALL-E summary So, VALL-E is an AR or NAR model? VALL-E is a hybrid model that leverages the strengths of both AR and NAR architectures. In section 6 Conclusion, Limitations, and Future Work you can see one important note:
Synthesis robustness: We observe that some words may be unclear, missed, or duplicated in speech synthesis. It is mainly because the phoneme-to-acoustic language part is an autoregressive model, in which disordered attention alignments exist and no constraints to solving the issue. The phenomenon is also observed in vanilla Transformer-based TTS, which was addressed by applying non-autoregressive models or modifying the attention mechanism in modeling. In the future, we would like to leverage these techniques to solve the issue.
It’s interesting to note that the authors acknowledge this limitation and plan to explore techniques from non-autoregressive models or modified attention mechanisms to address this issue in future work. Even state-of-the-art AR models struggle with limitations like disordered attention alignments, leading to synthesis robustness issues.
StyledTTS 2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
Github repo StyleTTS 2 is a state-of-the-art text-to-speech (TTS) model that leverages style diffusion and adversarial training with large speech language models (SLMs) to achieve human-level TTS synthesis. By modeling styles as a latent random variable through diffusion models, StyleTTS 2 is able to generate the most suitable style for the input text in diverse speech synthesis. The use of large pre-trained SLMs, such as WavLM, as discriminators with differentiable duration modeling enables end-to-end training and improves speech naturalness.
Style Diffusion
StyleTTS 2 models speech x as a conditional distribution: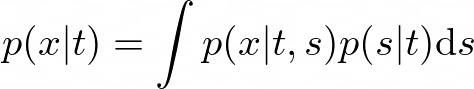
where t represents the phonetic content, and s is a latent variable representing the generalized speech style. This style variable s is sampled using Efficient Diffusion Models (EDM), which follow the combined probability flow and time-varying Langevin dynamics. By modeling styles as a latent random variable through diffusion models, StyleTTS 2 can generate the most suitable style for the input text, enabling diverse speech synthesis. Adversarial Training with Large SLMs StyleTTS 2 employs large pre-trained SLMs, such as WavLM, as discriminators during training. This adversarial training, combined with the proposed differentiable duration modeling, results in improved speech naturalness.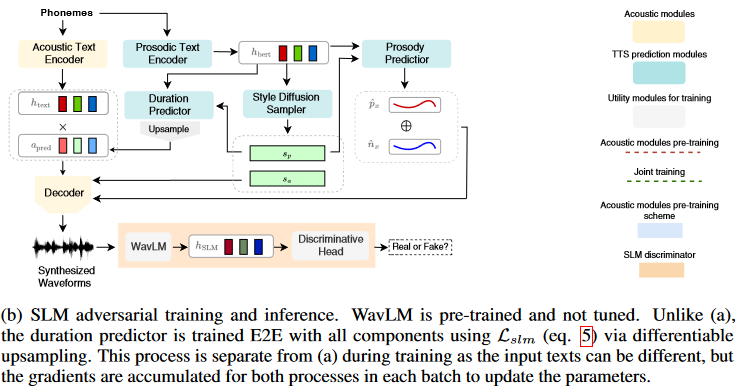
Key Contributions
- Differentiable Upsampling and Fast Style Diffusion: StyleTTS 2 introduces a differentiable upsampling method that allows for generating speech samples during training in a fully differentiable manner, similar to inference. These generated samples are used to optimize the loss function involving the large pre-trained SLM, enabling end-to-end training of all components.
- Efficient Style Sampling: To enable fast style sampling during inference, StyleTTS 2 uses the ancestral DPM-2 solver instead of the 2nd-order Heun method, allowing for fast and diverse sampling without significantly impacting inference speed.
- Multispeaker Modeling: For multispeaker settings, StyleTTS 2 models p(s|t, c), where c is a speaker embedding obtained from a reference audio of the target speaker. This speaker embedding is injected into the transformer model using adaptive layer normalization.
Known Issues It’s worth noting that StyleTTS 2 has a known issue where loud white noise can occur on short texts when the `embedding_scale` parameter is set to a value greater than 1 (see GitHub issue #46). Hybrid AR-NAR Approach perspective StyleTTS 2 presents a novel and promising approach to text-to-speech synthesis by combining the strengths of both autoregressive (AR) and non-autoregressive (NAR) models. This hybrid architecture leverages the power of large pre-trained SLMs, which are typically autoregressive models, while incorporating the diversity and expressiveness offered by diffusion models, which are non-autoregressive. By combining the pre-trained SLM with the style diffusion process, StyleTTS 2 effectively creates a hybrid architecture that combines the strengths of both AR and NAR models. The SLM provides a strong foundation for capturing sequential dependencies and generating high-quality speech, while the diffusion process introduces diversity and expressiveness, enabling the generation of natural-sounding speech with appropriate styles and characteristics. The combination of style diffusion and adversarial training with large SLMs has proven to be a powerful approach for generating natural and expressive speech.
Next chapter
Part 5: Non-autoregressive models review📝 Author: Nick Ovchinnikov
Original article: https://medium.com/@peechapp/text-to-speech-models-part-4-autoregressive-and-hybrid-models-review-abeb2b5ec3ec
Level up your reading with Peech
Boost your productivity and absorb knowledge faster than ever.
Start now